

4.3 Prep_Raw.sh

After development of each of the software pieces described previously in this section, the entire data cleaning process was driven by the program prep_raw.sh. This procedure was run on all of the swaths that were output from SyncPrep to create the first version of the ASF online Seasat raw data archive (the fixed_ files). Analysis of these results is covered in the next section. What follows here are examples of the prep_raw.sh process and intermediate outputs.
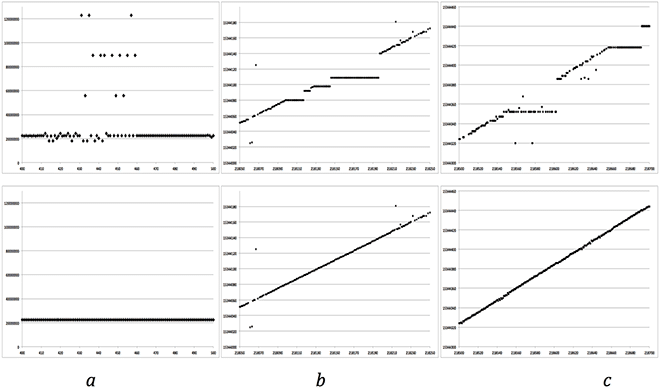
Time Filtering in Stages: Each plot shows range line number versus MSEC metadata value. Top row is before filtering; bottom is after. From left to right: (a) Stage 1 — attempt to fix all time values > 513 from the linear trend. (b) Stage 2 — fix stair steps resulting from sticking clock on satellite. (c) Stage 3 — final linear fix before discontinuity removal.
Data Set #1
Decoded Signal Data
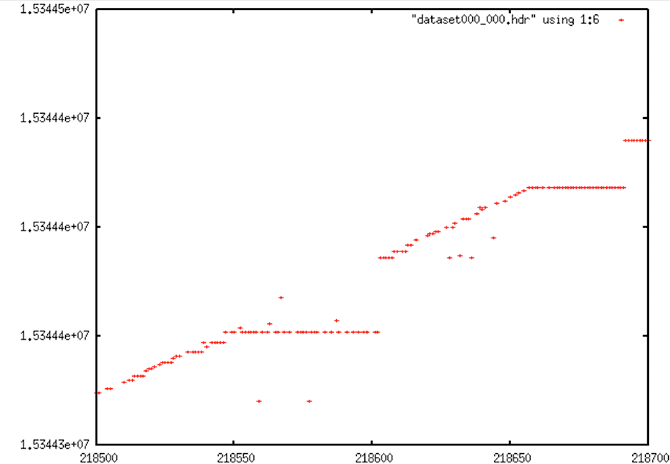
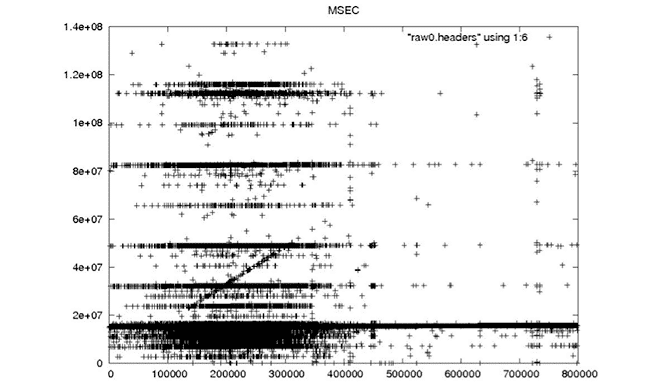
Time Gap Corrections
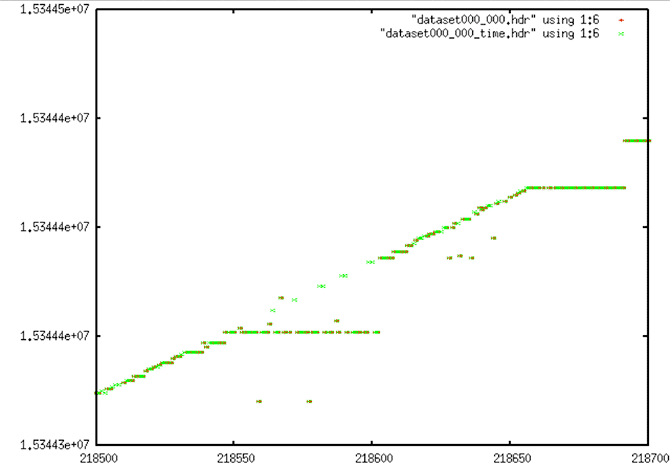
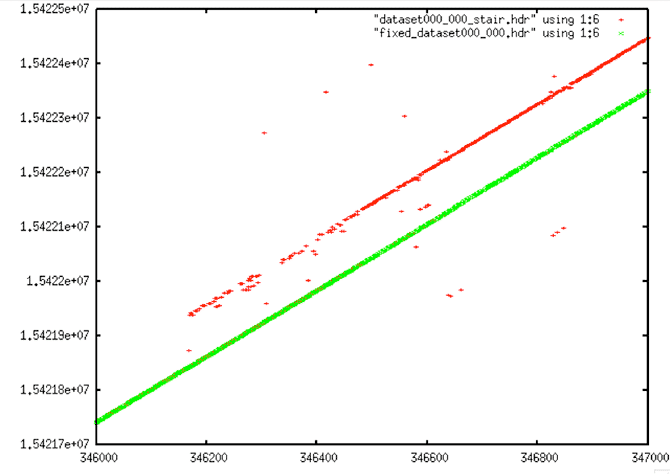
Stair Corrections
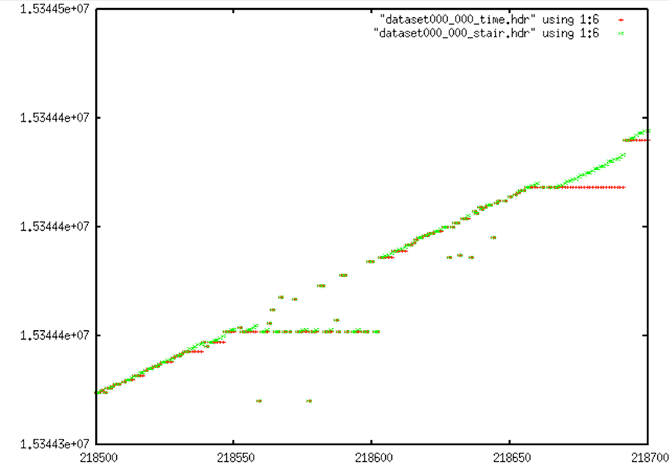
Time Value Corrections
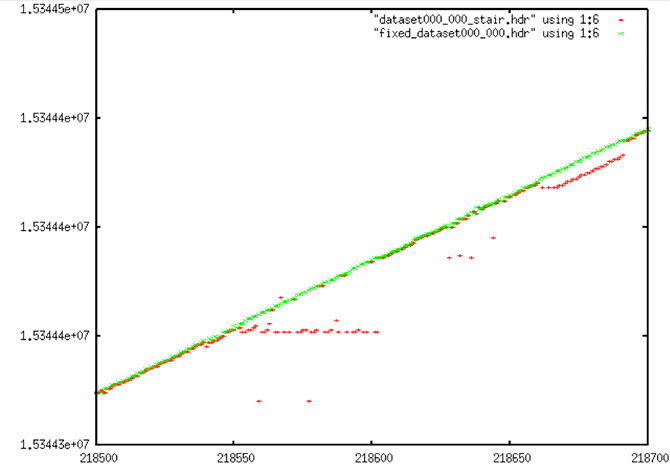
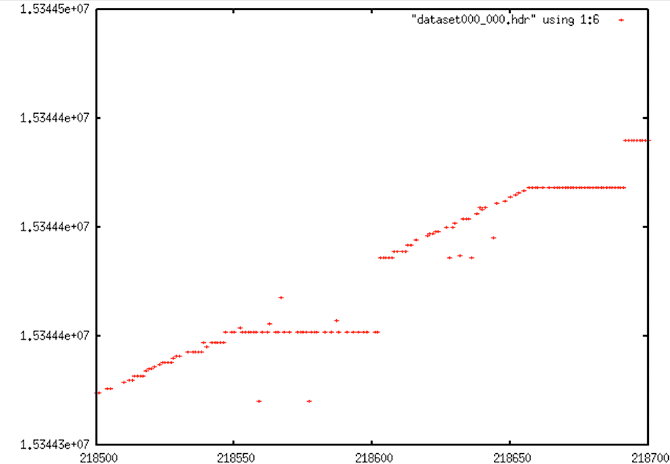
Data Set #2
Decoded Signal Data
Time Gap Corrections
Stair Corrections
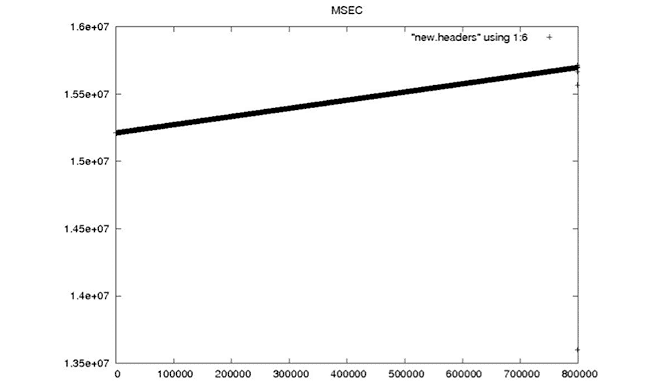
Linear Time Restored
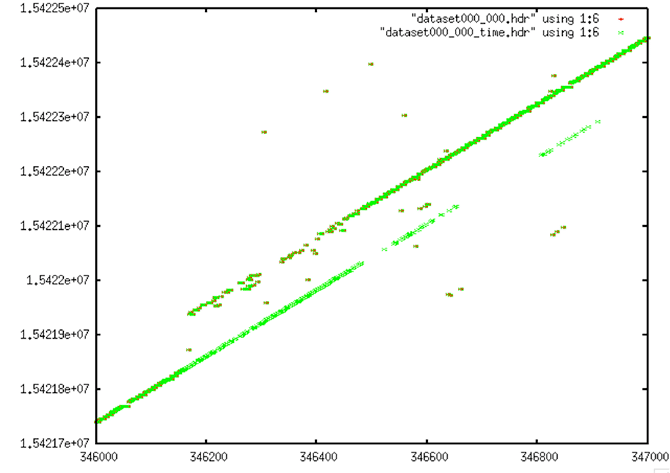
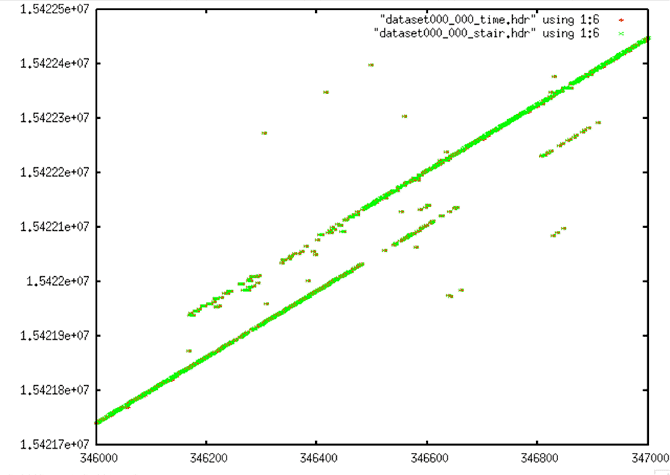
Decoded Time Data from Section 2.1 Examples
Cleaned Time Data from 2.1 Examples
4.4 Results of Prep_Raw.sh
By November 15, 2012, the beta version of prep_raw.sh was delivered to ASF operations. It was run on individual swaths at first, with results spot-checked. Once confidence in the programs increased, all remaining Seasat swaths were processed through this decoding and cleaning software en masse. Overall, from the 1,840 files that SyncPrep created, 1,470 were successfully decoded, and 1,399 of those made it through the prep_raw.sh procedure to create a set of fixed decoded files. The files that failed comprise 242 GB of data, while 3,318 GB of decoded swath data files were created.
| Processing Stage | #files | Size (GB) |
|---|---|---|
| Capture | 38 | 2160 |
| SyncPrep | 1840 | 2431 |
| Original Decoded | 1470 | 3585 |
| Fixed Decoded | 1399 | 3318 |
| Good Decoded | 1346 | 3160 |
| Bad Decoded | 53 | 157 |
Summary of Data Cleaning
93% of data made it through SyncPrep
92% of that data decoded (assume 1.6 expansion)
93% of that data was “fixed”
95% of that data considered “good”
OVERALL: ~80% of SyncPrep’d data is “good”
Reasons for Failures
- SyncPrep: Not all captured files could be interpreted by SyncPrep
- Original Decoded: Because the decoder needs to interpret the subcommutated headers, it is more stringent on maintaining a “sync lock” than SyncPrep
- Fixed Decoded: Some files are so badly mangled that a reasonable time sequence could not be recovered
- Bad Decoded: Several subcategories of remaining data errors are discussed in section 5
4.5 Addition of fix_start_times
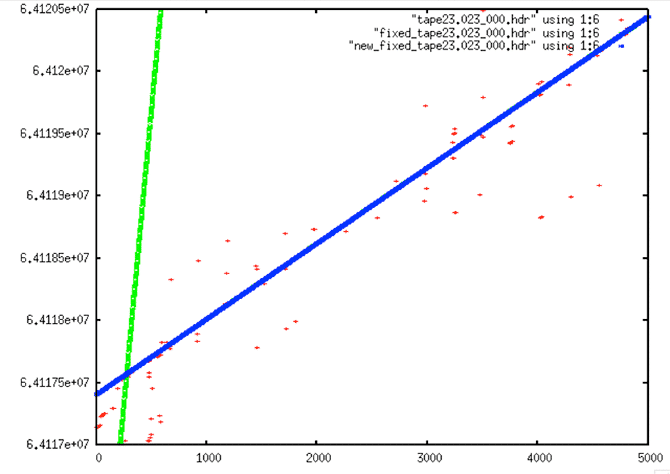
During analysis of the fixed metadata files, it was discovered that bad times occurred at the beginning of many files. This problem was not a big surprise; the nature of the sync code search is such that many errors occur in places where the sync codes cannot be found. This is why the files were broken in the first place. So, it is expected that the beginning of a lot of the swath files will have bad metadata, which means bad times. When bad times are linearly trended, the results are unpredictable.
Bad Start Time Examples
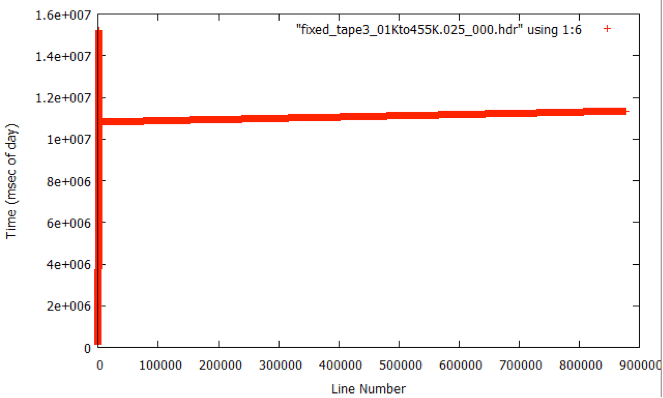
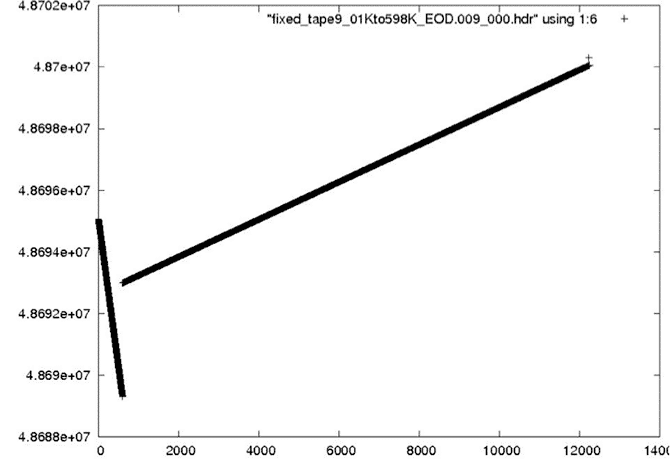
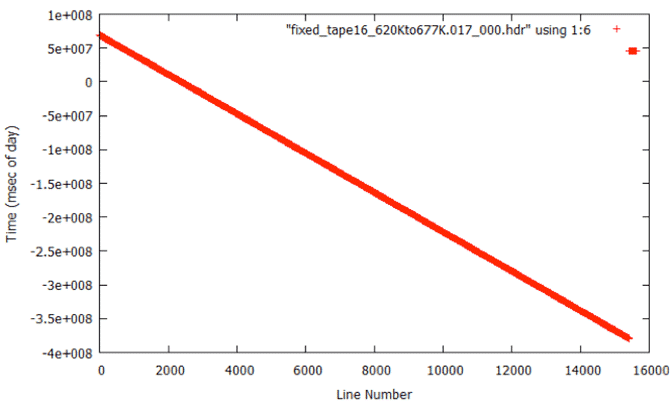
To fix this problem, yet another level of filtering was added to the processing flow – this time a post-filter to fix the start times. The code fix_start_times replaces the first 5,000 times in a file with the linear trend resulting from the next 10,000 lines in the file. This code was added as a post-processing step to follow prep_raw.sh and run on all of the decoded swath files.

Final Processing Flow: With the addition of the fix_start_times code, the processing flow for data decode and cleaning is finally completed.
Fixed Start Time Examples
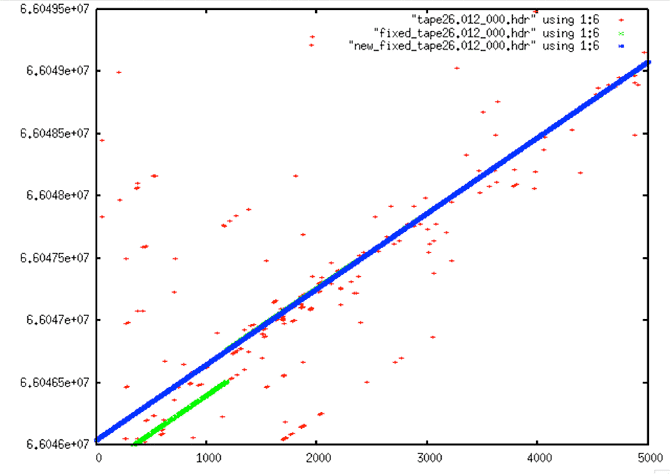
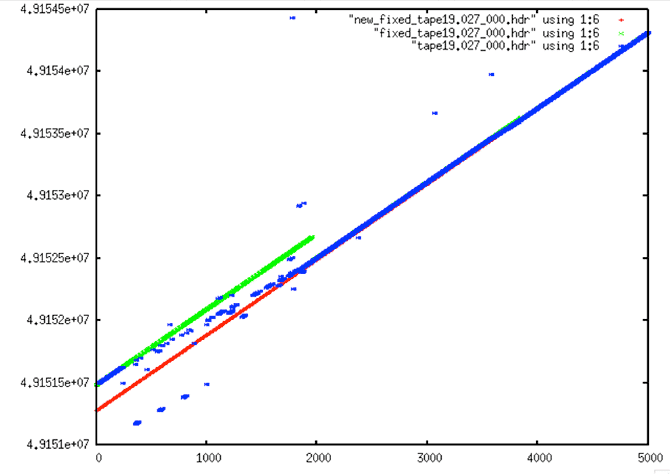
Written by Tom Logan, July 2013
